Summary: Learn how continuous attack surface mapping helps you track down shadow IT, secure exposed assets, and fix critical blind spots before attackers find them.
In an ideal world, every asset, API, and cloud instance would be documented and tracked from the moment it’s spun up. In practice, however, things move fast. Shadow IT, forgotten dev environments, and temporary subdomains often stay alive long after they’ve served their purpose, quietly expanding your organization’s attack surface without anyone noticing.
This is the “unknown” part of your attack surface, and it’s exactly what attackers look for first.
In this guide, we’ll look at how attack surface mapping works in a practical sense, the difference between internal and external exposures, and how to stay ahead of “asset drift” before it turns into a security incident.
Key takeaways
Infrastructure moves too fast for point-in-time scans. Continuous monitoring is the only way to catch shadow IT, forgotten subdomains, and active legacy projects.
External mapping finds what is exposed to the internet, but internal mapping is crucial for cutting off the lateral pathways attackers use once they bypass the perimeter.
Vulnerability scanners only check the IPs they are told to look at. Mapping your environment dictates what actually needs scanning in the first place.
By automatically classifying assets and mapping attack vectors, security teams can prioritize reachable threats instead of being overwhelmed by low-level alerts.
Between rapid DevOps deployments, API sprawl, and multi-cloud environments, manual tracking is impossible. Effective mapping requires direct cloud integrations and automated asset tagging to maintain a single source of truth.
What is attack surface mapping?
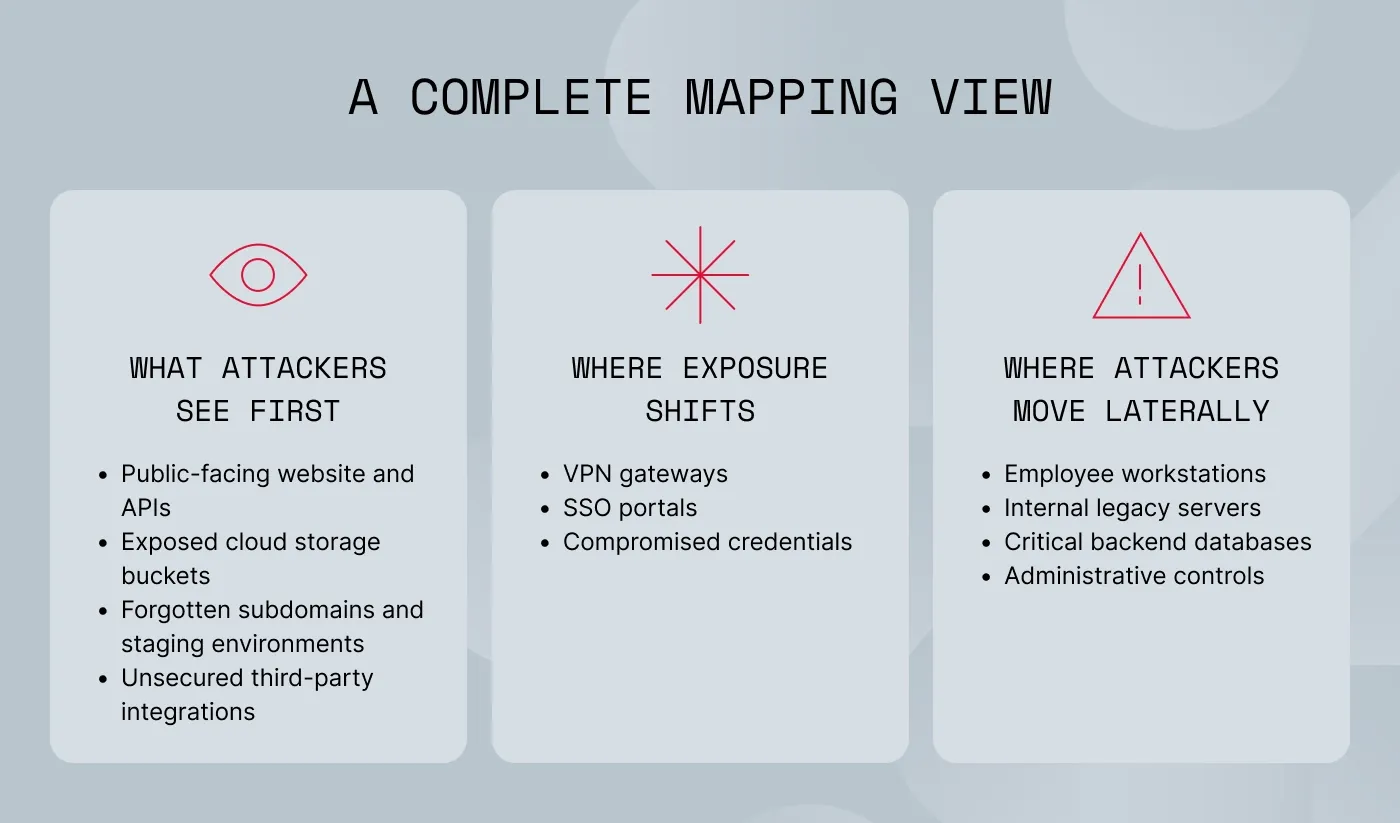
Attack surface mapping is the continuous process of identifying, classifying, and monitoring every potential entry point across an organization’s infrastructure. Relying solely on a static asset inventory usually leaves blind spots, especially when dealing with shadow IT, unmanaged cloud instances, or legacy projects that were never properly decommissioned. But mapping the attack surface exposes the true, real-time scope of your digital attack surface from an adversary’s perspective. When mapping attack surface environments, the focus expands to find exposed assets on the external perimeter while simultaneously tracking internal entry points that could allow lateral movement if an initial breach occurs.
This deep approach to surface mapping uncovers immediate operational risks, pinpointing the exact misconfigurations, expired certificates, and open services that attackers look for first. And because infrastructure changes constantly through everyday development and scaling, effective attack surface management demands ongoing monitoring rather than a single, point-in-time scan.
External vs. internal attack surface mapping
When organizations talk about their digital attack surface, they usually focus on the outside—things like public websites, open cloud storage, or third-party integrations, which makes sense. External attack surface mapping is all about finding the assets that anyone on the internet can see and potentially exploit.
But stopping there leaves a blind spot.
As we see in many modern cyberattacks, once a hacker gets past those initial defenses, often by stealing VPN credentials or exploiting an SSO portal, they don’t just stop, they move inside the network.
Internal surface mapping is useful in this situation. Instead of looking at what is exposed to the internet, it tracks the lateral pathways within your own infrastructure. It helps you understand exactly how a standard employee workstation might be connected to a highly sensitive core database.
To put it simply, you won’t get this complete picture if you only use a basic asset inventory. Examining both sides of the issue is necessary for effective attack surface management. Your team can identify the precise paths an attacker would take and stop them before a small external vulnerability becomes a significant internal compromise by using specialized attack surface mapping tools to conduct a thorough attack surface analysis.
How attack surface mapping actually works
If you’ve ever tried to manually track down every IT asset your company owns, you know it’s a futile effort. The infrastructure simply moves too fast. That’s why mapping your attack surface can’t be a manual, once-a-year project—it must be an automated, ongoing cycle. Here is a breakdown of how the process actually works on the ground.
Discovering your scattered assets
The first step is finding everything that actually belongs to your organization. A static asset inventory usually falls short here, mostly because it only reflects what was officially documented at a specific point in time. In reality, you need to actively look for the forgotten subdomains, stray public IP addresses, and unmanaged cloud resources that your team might have lost track of over the years.
This also includes rooting out APIs and exposed services that were spun up for a single project and left running. Doing this manually is nearly impossible, which is why solutions like attack surface management handles it for you. By continuously scanning the web, the platform automatically catalogs these assets, which gives you a true picture of your environment.
Classifying and prioritizing the risks
Discovering thousands of exposed endpoints is a huge step forward for visibility. However, if you treat every single one of them with the same level of urgency, your security team will burn out in a week. Once your assets are discovered, they have to be categorized based on business criticality, data sensitivity, and overall exposure level. An outdated marketing blog simply doesn’t carry the same risk as an internal billing database.
Vulnerability intelligence and scanning
It’s time to test those particular assets now that you know what you have and what matters. In order to find known vulnerabilities and weak security settings everywhere, this phase entails running ongoing scans. It does much more than simply look for software patches that are missing. This continuous surface mapping actively searches for critical misconfigurations, such as a firewall rule that was incorrectly applied during a late-night update or a cloud storage bucket that was inadvertently set to public access.
Mapping attack vectors and analyzing paths
This is where attack surface analysis really proves its value. By mapping the technical connections between your assets and analyzing data flows, you can determine exactly how a hacker might move through the network. If they breach a seemingly harmless external application, what core systems can they reach next? Tracing these exact paths when mapping attack surface environments helps you break the chain of compromise before an incident has the chance to escalate.
Reporting and tracking remediation
Finally, all of this data needs to translate into action. Generating clear, actionable reports allows your IT teams to fix the issues without digging through endless logs. And because the infrastructure never stops changing, tracking that remediation process is the only way to ensure the port was actually closed and the risk was fully eliminated.
Why vulnerability management relies on attack surface mapping
Running a vulnerability scanner on a regular schedule is a standard security practice, but a scanner only checks the IP addresses and domains it is explicitly told to look at. So, if your IT department doesn’t know a legacy dev server exists, the scanner doesn’t either.
To fix this disconnect, you have to know what you actually own before you start looking for software flaws, which really is the core value of attack surface mapping. It dictates exactly which assets require scanning in the first place by actively pulling unmanaged, forgotten systems out of the dark. As a result, a stray API or an old staging environment isn’t simply ignored just because it never made it onto an official IT spreadsheet.
Once you establish a complete, honest picture of your attack surface, your entire vulnerability management program suddenly becomes much more practical. Continuous surface mapping naturally highlights the high-risk exposed services that need immediate attention. It gives you the necessary context to look at an alert and realize a server isn’t just missing a patch—it’s unpatched and directly facing the public internet.
Related articles

Aurelija EinorytėJan 15, 20258 min read

Agnė SrėbaliūtėFeb 25, 20268 min read
Why mapping your attack surface is harder than it looks
Getting a clear, accurate picture of your network sounds straightforward on paper, but the reality of managing modern infrastructure makes attack surface mapping very complex. For starters, the sheer speed of rapid DevOps deployments means new code, servers, and services go live on a daily basis. When you combine that pace with the inevitable creep of shadow IT—where different departments bypass IT entirely to spin up their own SaaS tools—keeping track of everything becomes tough. Even when you do manage to find a rogue testing server, you are often hit with incomplete asset ownership data. Figuring out exactly who spun it up and who is actually responsible for patching it can sometimes take longer than fixing the flaw itself.
The architecture of the network also works against you—we rarely rely on a single, neat data center anymore. Instead, companies operate across highly fragmented multi-cloud environments, spreading data and services across AWS, Azure, and Google Cloud simultaneously. To make all those different environments talk to each other, developers rely heavily on application programming interfaces. Consequently, API sprawl has become one of the most dangerous blind spots in surface mapping. Countless old, undocumented endpoints are frequently left active and exposed long after the original project was retired.
Then there are the external business factors that can suddenly inflate your attack surface overnight. Mergers and acquisitions are prime examples. When you buy a company, you inherit not only its revenue but also its technical debt, forgotten infrastructure, and undocumented vulnerabilities. On top of that, you have to factor in third-party risk visibility—your internal team might have your own house in perfect order, but if a vendor you integrate with gets compromised, that trusted connection easily becomes a direct pathway straight into your network.
How to actually get attack surface mapping right
If you treat attack surface mapping as a quarterly or even monthly project, you’re always going to be a few steps behind the reality of your network. By the time a standard report is finally generated, your developers have likely spun up 3 new staging environments and retired an old API.
To actually keep up with that pace, you have to move entirely from point-in-time scans to continuous monitoring. And scanning from the outside in will only get you so far. The most effective approach is setting up direct integration with cloud provider APIs. Tying directly into AWS, Azure, or Google Cloud means that the exact second a new instance is created, your security tools know about it.
Of course, just finding a stray server isn’t enough either—you still need to know what it does and who is responsible for patching it, which makes automated asset tagging an absolute necessity. When every new resource is automatically labeled with its business context and owner, you save your team hours of investigation down the road. To keep those records honest, you also need to establish a habit of regular reconciliation with your Configuration Management Database (CMDB). When your surface mapping tools continuously feed accurate data into the CMDB, you naturally bridge the gap between departments. Suddenly, IT, security, and DevOps are collaborating around a single, reliable source of truth instead of arguing over whose spreadsheet is right.
Pulling all of these practices together is the only way to genuinely protect your attack surface, but trying to build and maintain that kind of automated workflow from scratch takes a lot of engineering time. So, for most teams, the smartest move is simply adopting a purpose-built solution like NordStellar’s Attack Surface Management. It continuously monitors your infrastructure, immediately flagging misconfigurations and using active validation to prove which risks are actual exploits. Instead of making your team sort through endless alerts manually, NordStellar gives you a prioritized view of your real vulnerabilities, so you can just fix them before anyone else exploits them.
Ready to see exactly what your network looks like from the outside? Get a free NordStellar trial to automatically map and secure your exposed assets.

Aistė Medinė
Editor and Copywriter
An editor and writer who’s into way too many hobbies – cooking elaborate meals, watching old movies, and occasionally splattering paint on a canvas. Aistė's drawn to the creative side of cybercrime, especially the weirdly clever tricks scammers use to fool people. If it involves storytelling, mischief, or a bit of mystery, she’s probably interested.